Case Discriminating OCR Neural Network
Select an example or use your cursor to draw a letter (a-Z). Some letters—cijklmopsuvwxyz—when drawn smaller will be perceived as lowercase. Source is linked below. Numbers not supported :)
| Prediction | Probability |
|---|---|
| Loading | ... |
A Serious Case of the Uppers and Lowers
I set out to create a Tensorflow neural network that could properly detect letter case. To make it come to life, I also wanted the ability to scribble in characters and make predictions on the fly. Hopefully it would feel somewhat natural to use too. I’m happy with how it turned out!
The TLDR version is it didn’t require a better model, just better data. I spent 99.9% of my time just massaging the data within the wonderful tensorflow datasets api.

Starting out I used the EMNIST dataset. I soon discovered it to be normalized in a way which is impossible to discriminate between letter case. Specifically for characters—cijklmopsuvwxyz. A few variants of the EMNIST dataset are provided to help with this. They do so by merging character classes together; essentially pretending some lowercase letters don’t exist as a class.
I decided my best approach would be to use the EMNIST/By_Class dataset. It has all the character classes and retains the full dataset. To understand what exactly we’re dealing with here, a sampling of case ambiguous characters is worth a thousand words:
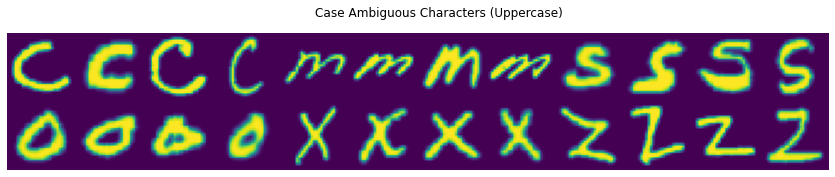
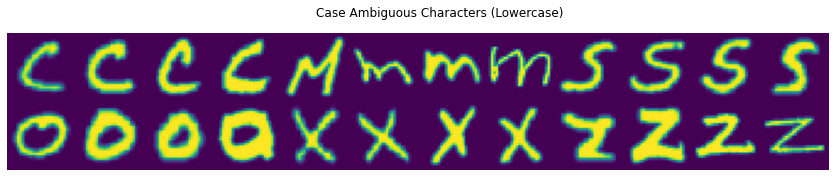
Relying solely on these example images, I can’t decipher which of these should be lower or upper case. As it turns out, after some experimentation—a neural network struggles with this too!
For these letters the discriminating factor for case is—relative glyph size. Therfore all the lowercase examples could simply be scaled down to solve this. Ultimately I did something slightly more nuanced; the scale of a letter is a function of this matrix:
| Lowercase | Uppercase | |
|---|---|---|
| Case Ambiguous | Small-Med | Med-Large |
| Not Case Ambiguous | Small-Large | Small-Large |
Uniform xy translations are also applied to each image. How much translation is also a function of the matrix. Smaller glyphs get moved around more than larger glyphs—which are closer to the edges. After post-processing, this is how things are now looking:
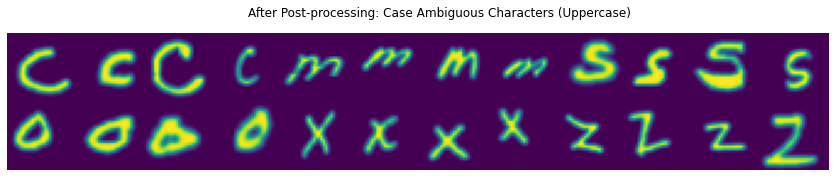
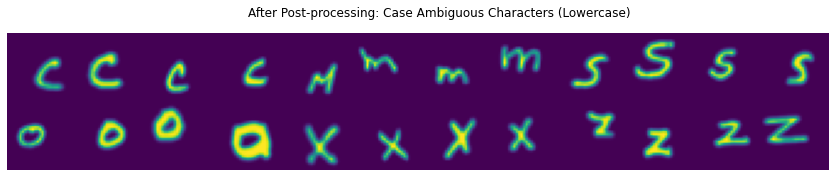
It’s very subtle but makes a world of difference for training this network. Two things immediately stand out when compared to the prior example images:
- Loss of brightness from re-scaling glyphs.
- Notice the one ‘s’ that is larger than some ‘S’ examples.
There are some minor blips in the confusion matrix that we’ll see below, but nothing bad. In practice these seem to not be an issue. I do think further refinements from tuning the glyph scale matrix could definitely be had.
The post-processing is applied to both the training and validation/test data. Before beginning model training, we still have one unresolved data issue—unbalanced training data:
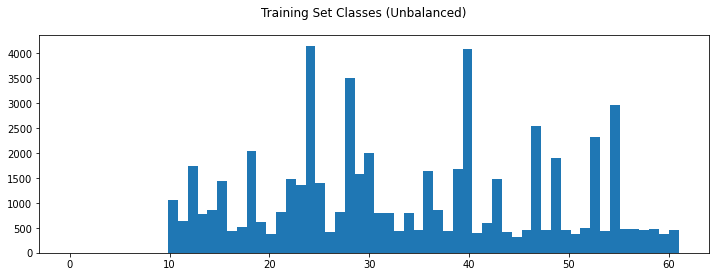
Some classes have many more examples than others. The problem here is the neural network won’t learn discriminating features as well; instead it’ll learn to make safe bets on the more popular classes. Balancing the classes so they are seen roughly equally is the fix.
Classes 0-9 are missing and just happen to correlate to the numeric characters ‘0’-‘9’, which I removed from the dataset. To even out the classes I came up with a simple duplication algorithm—based on class frequency and a unifom distribution. It’s not perfectly balanced, but more than good enough. It runs in a single pass with flat_map (very fast):

I applied the post-processing after balancing so all the duplicate examples would be transformed into something a little different. Finally the model is ready to train! A basic LeNet is standard for this problem domain—two convolution and max-pooling layers followed by two fully connected layers.
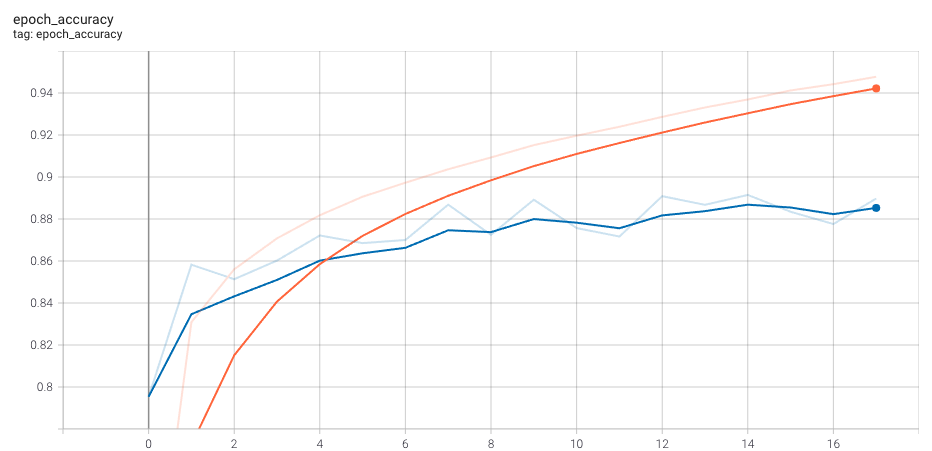
The orange line is the training validation and the blue is test validation. After 18 epochs the network is no longer learning. Tensorflows patience settings kick in and automatically stop the training process before overfitting occurs. I actually had to dial back the patience after a prior run did overfit. Test validation will turn south when that happens.
I introduced some elements of randomness when post-processing and balancing the data. I typcially see validation accuracy in the high 80s or low 90s, so YMMV between runs—Is this good or bad? Let’s examine the confusion matrix for insight.
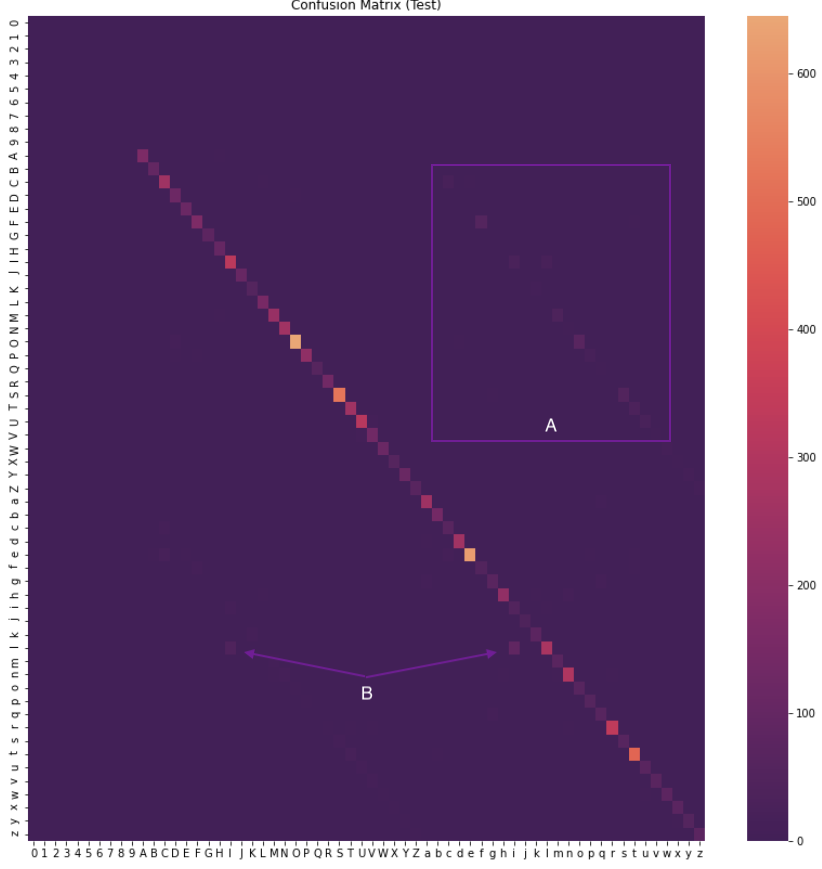
The confusion matrix is a heatmap of labels vs. predictions. Color off the main diagonal are incorrect predictions that our network made. The diagonal has wildly varying color/intensity because I left the validation dataset unbalanced. Otherwise this would be cause for concern.
- Area A: These are incorrect predictions for case ambiguous characters. The network perceived the correct letter but the wrong case here. There is a middle ground where the uppercase/lowercase version of a letter are similar in size. Tuning the glyph scale matrix so there is more delineation may help.
- Area B: l, I and L, i get mixed up sometimes. I chalk this up to glyph similarity and the varying way people write these letters. Scanning over a small set of false positive examples reaffirms my thinking.
After experimentally validating with tfjs in the browser, I feel like this network achieved what I had set out to create!
Resources
- Source code: https://github.com/subprotocol/cdnn/blob/master/cdnn.ipynb
- EMNIST Dataset: https://www.nist.gov/itl/products-and-services/emnist-dataset