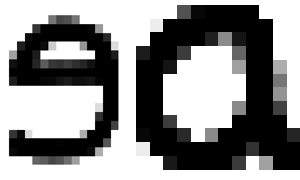
Augmenting Education with Machine Learning
Proof of concept demonstrating the potential for neural networks to scale and optimize the classroom learning environment.
View
Case Discriminating OCR Neural Network
Tensorflow neural network trained on post-processed EMNIST dataset—capable of perceiving letter case.
View
Curve Fitting using Genetic.js
From a plot of vertices, this genetic algorithm optimizes a continious function to best fit the data (aka least squared error).
View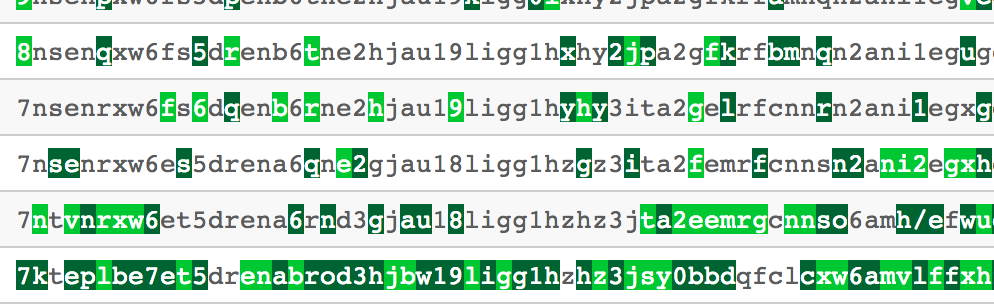
Genetic.js Hello World
The Hello World of Genetic Algorithms is a simple phrase solver. While useless in terms of utility, it is probably the simplest way to understand this class of algorithm.
View
Genetic.js
An advanced evolutionary and genetic algorithm library for Javascript. Lightweight, hackable, and features seamless webworker support.
View
Verlet Spiderweb
This web was spun using sinusoidal functions, distance tensioners, and pin constraints to hold it all up.
View
Verlet Fractal Trees
Recursively generated fractal tree demonstrating both distance and angular constraints.
View
Verlet Cloth Simulation
Lighted translucent cloth simulation. Color and opacity are both controlled by the local-pull of the fabric.
View
Apache Spark with Avro on S3
Example code that demonstrates how to get Apache Spark, Apache Avro and Amazon S3 all working together smoothly in EC2.
View
Spark, Darling of Bigdata
Introduction to Spark, a powerful and fast real-time map/reduce framework.
View
A week of Verlet-JS
The little (physics) engine that could.
View
Verlet Hello World
Demonstrating draggable objects and constraint stiffness coefficients.
View
Introducing Verlet-JS
An open source physics engine made for constructing 2D dynamic body simulations.
View